用于机器学习模型组合的 Python 工具箱

项目描述
部署 & 文档 & 统计







构建状态 & 覆盖 & 可维护性 & 许可证






combo是一个综合的 Python 工具箱,用于结合机器学习 (ML) 模型和分数。 模型组合可以被认为是集成学习的一个子任务,并已广泛应用于现实世界的任务和 Kaggle [ 3 ]等数据科学竞赛中。 自成立以来, Combo已在各种研究工作中使用/引入[ 7 ] [ 11 ]。
组合库支持来自关键 ML 库(如scikit-learn、 xgboost和LightGBM )的模型和分数的组合,用于分类、聚类、异常检测等关键任务。一些有代表性的组合方法见下图。
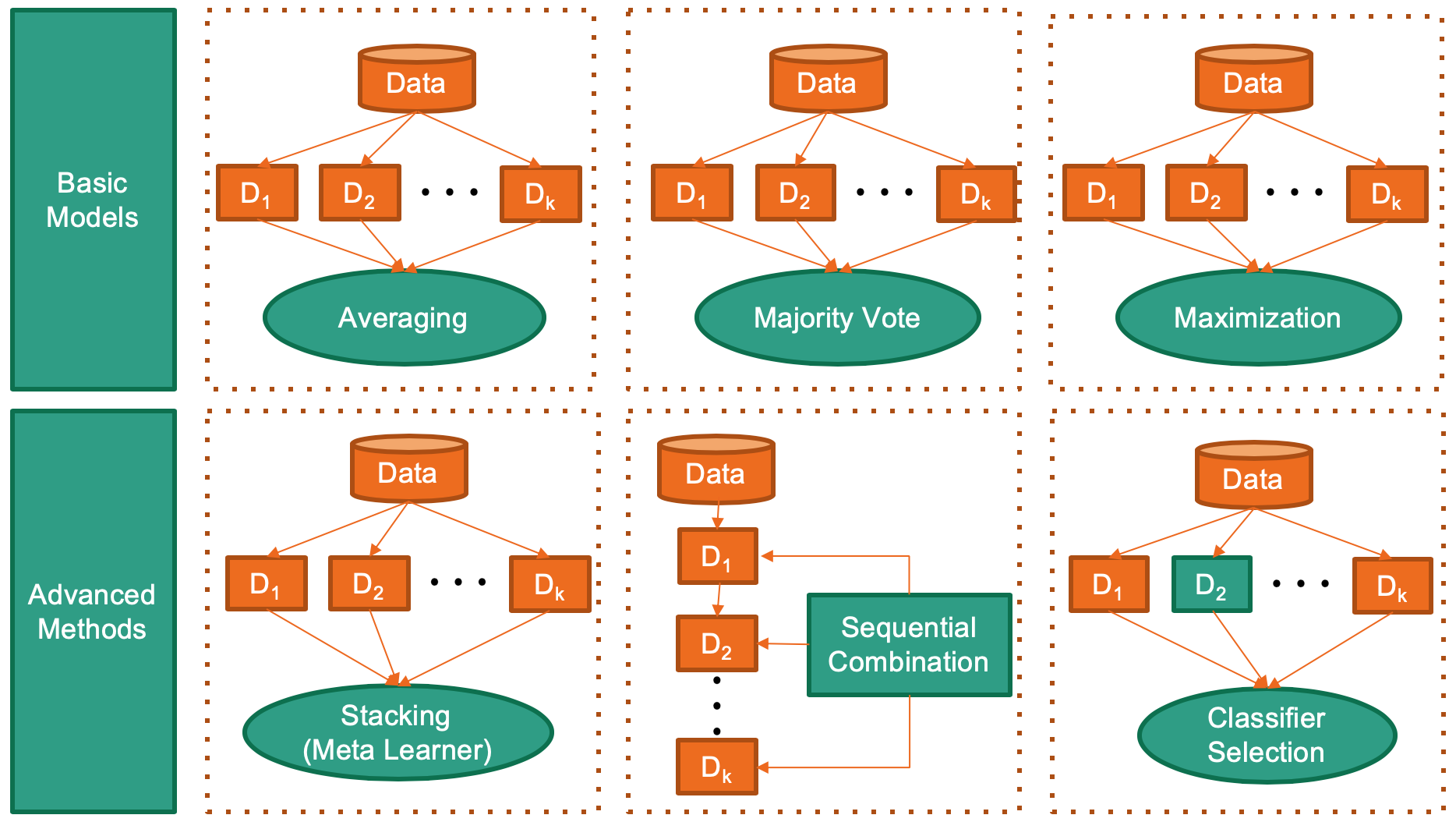
组合适用于:
跨各种算法的统一 API、详细文档和交互式示例。
先进和最新的模型,例如 Stacking/DCS/DES/EAC/LSCP。
全面覆盖分类、聚类、异常检测和原始分数。
API 演示:
from combo.models.classifier_stacking import Stacking
# initialize a group of base classifiers
classifiers = [DecisionTreeClassifier(), LogisticRegression(),
KNeighborsClassifier(), RandomForestClassifier(),
GradientBoostingClassifier()]
clf = Stacking(base_estimators=classifiers) # initialize a Stacking model
clf.fit(X_train, y_train) # fit the model
# predict on unseen data
y_test_labels = clf.predict(X_test) # label prediction
y_test_proba = clf.predict_proba(X_test) # probability prediction引用组合:
组合论文发表在 AAAI 2020(演示轨道)。如果您在科学出版物中使用组合,我们将不胜感激引用以下论文:
@inproceedings{zhao2020combo,
title={Combining Machine Learning Models and Scores using combo library},
author={Zhao, Yue and Wang, Xuejian and Cheng, Cheng and Ding, Xueying},
booktitle={Thirty-Fourth AAAI Conference on Artificial Intelligence},
month = {Feb},
year={2020},
address = {New York, USA}
}
或者:
Zhao, Y., Wang, X., Cheng, C. and Ding, X., 2020. Combining Machine Learning Models and Scores using combo library. Thirty-Fourth AAAI Conference on Artificial Intelligence.
关键链接和资源:
awesome-ensemble-learning(与集成学习相关的书籍、论文等)
目录:
安装
推荐使用pip进行安装。请确保 安装了最新版本,因为组合经常更新:
pip install combo # normal install
pip install --upgrade combo # or update if needed
pip install --pre combo # or include pre-release version for new features或者,您可以克隆并运行 setup.py 文件:
git clone https://github.com/yzhao062/combo.git
cd combo
pip install .所需的依赖项:
Python 3.5、3.6 或 3.7
工作库
matplotlib(运行示例可选)
numpy>=1.13
数>=0.35
pyod
scipy>=0.19.1
scikit_learn>=0.20
Python 2 注意事项:Python 2.7 将于 2020 年 1 月 1 日停止维护(见官方公告)。为了与 Python 更改和 Combo 的依赖库(例如 scikit-learn)保持一致, Combo 仅支持 Python 3.5+,我们鼓励您使用 Python 3.5 或更高版本来获取最新功能和错误修复。更多信息可以在Moving to require Python 3中找到。
API 备忘单和参考
完整的 API 参考:(https://pycombo.readthedocs.io/en/latest/api.html)。以下 API 对于大多数模型都是一致的(API 备忘单:https ://pycombo.readthedocs.io/en/latest/api_cc.html )。
fit(X, y):拟合估计器。y 对于无监督方法是可选的。
predict(X):一旦拟合了估计器,就对特定样本进行预测。
predict_proba(X):一旦拟合了估计器,预测样本属于每个类的概率。
fit_predict(X, y):拟合估计器并在 X 上进行预测。对于无监督方法,y 是可选的。
对于原始分数组合(生成分数矩阵后),直接使用 “score_comb.py”中的各个方法。原始分数组合 API:(https://pycombo.readthedocs.io/en/latest/api.html#score-combination)。
实现的算法
Combo按任务对组合框架进行分组。通用方法是可以应用于各种任务的基本方法。
任务 |
算法 |
年 |
参考 |
|---|---|---|---|
一般用途 |
平均和加权平均:所有分数/预测结果的平均值,可能带有权重 |
不适用 |
|
一般用途 |
最大化:通过取最大分数进行简单组合 |
不适用 |
|
一般用途 |
中值:取所有分数/预测结果的中值 |
不适用 |
|
一般用途 |
多数票和加权多数票 |
不适用 |
|
分类 |
SimpleClassifierAggregator:通过上述通用方法组合分类器 |
不适用 |
不适用 |
分类 |
DCS:动态分类器选择(使用局部准确度估计的多个分类器的组合) |
1997 |
|
分类 |
DES:动态集成选择(从动态分类器选择到动态集成选择) |
2008年 |
|
分类 |
Stacking(元集成):使用元学习器学习基分类器结果 |
不适用 |
|
聚类 |
Clusterer Ensemble:通过relabeling组合多个聚类结果的结果 |
2006年 |
|
聚类 |
使用证据积累 (EAC) 组合多个聚类 |
2002年 |
|
异常检测 |
SimpleDetectorCombination:通过上述通用方法组合异常检测器 |
不适用 |
|
异常检测 |
最大值平均值(AOM):将基础检测器分成子组取最大值,然后取平均值 |
2015 |
|
异常检测 |
平均值最大值(MOA):将基础检测器分成子组取平均值,然后最大化 |
2015 |
|
异常检测 |
XGBOD:一种用于异常值检测的半监督组合框架 |
2018 |
|
异常检测 |
局部选择性组合 (LSCP) |
2019 |
下面提供了所选实施模型之间的比较(图, compare_selected_classifiers.py,交互式 Jupyter Notebooks)。对于 Jupyter Notebooks,请导航到“/notebooks/compare_selected_classifiers.ipynb”。
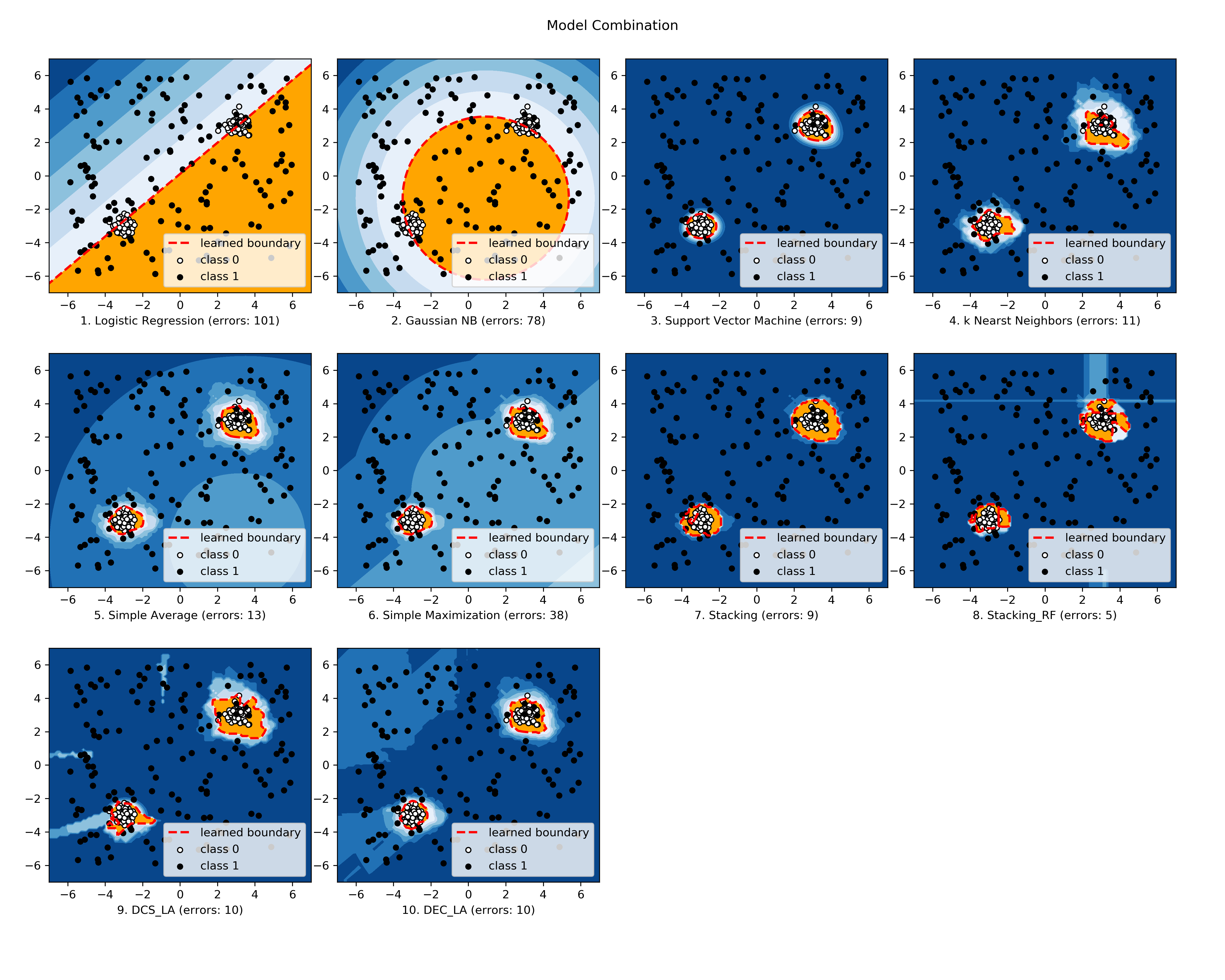
所有实现的模式都与示例相关联,请查看 “组合示例” 以获取更多信息。
堆叠/DCS/DES 示例
“examples/classifier_stacking_example.py” 演示了堆叠(元集成)的基本API。“examples/classifier_dcs_la_example.py” 演示了通过局部精度进行动态分类器选择的基本API。“examples/classifier_des_la_example.py” 演示了通过局部精度进行动态集成选择的基本 API。
值得注意的是,所有这些模型的基本 API 都是一致的。
将一组分类器初始化为基本估计器
# initialize a group of classifiers classifiers = [DecisionTreeClassifier(random_state=random_state), LogisticRegression(random_state=random_state), KNeighborsClassifier(), RandomForestClassifier(random_state=random_state), GradientBoostingClassifier(random_state=random_state)]使用 Stacking 进行初始化、拟合、预测和评估
from combo.models.classifier_stacking import Stacking clf = Stacking(base_estimators=classifiers, n_folds=4, shuffle_data=False, keep_original=True, use_proba=False, random_state=random_state) clf.fit(X_train, y_train) y_test_predict = clf.predict(X_test) evaluate_print('Stacking | ', y_test, y_test_predict)查看 classifier_stacking_example.py 的示例输出
Decision Tree | Accuracy:0.9386, ROC:0.9383, F1:0.9521 Logistic Regression | Accuracy:0.9649, ROC:0.9615, F1:0.973 K Neighbors | Accuracy:0.9561, ROC:0.9519, F1:0.9662 Gradient Boosting | Accuracy:0.9605, ROC:0.9524, F1:0.9699 Random Forest | Accuracy:0.9605, ROC:0.961, F1:0.9693 Stacking | Accuracy:0.9868, ROC:0.9841, F1:0.9899
分类器组合示例
“examples/classifier_comb_example.py” 演示了使用多个分类器进行预测的基本 API。请注意,所有其他算法的 API 都是一致/相似的。
将一组分类器初始化为基本估计器
# initialize a group of classifiers classifiers = [DecisionTreeClassifier(random_state=random_state), LogisticRegression(random_state=random_state), KNeighborsClassifier(), RandomForestClassifier(random_state=random_state), GradientBoostingClassifier(random_state=random_state)]使用简单的聚合器进行初始化、拟合、预测和评估(平均值)
from combo.models.classifier_comb import SimpleClassifierAggregator clf = SimpleClassifierAggregator(classifiers, method='average') clf.fit(X_train, y_train) y_test_predicted = clf.predict(X_test) evaluate_print('Combination by avg |', y_test, y_test_predicted)查看 classifier_comb_example.py 的示例输出
Decision Tree | Accuracy:0.9386, ROC:0.9383, F1:0.9521 Logistic Regression | Accuracy:0.9649, ROC:0.9615, F1:0.973 K Neighbors | Accuracy:0.9561, ROC:0.9519, F1:0.9662 Gradient Boosting | Accuracy:0.9605, ROC:0.9524, F1:0.9699 Random Forest | Accuracy:0.9605, ROC:0.961, F1:0.9693 Combination by avg | Accuracy:0.9693, ROC:0.9677, F1:0.9763 Combination by w_avg | Accuracy:0.9781, ROC:0.9716, F1:0.9833 Combination by max | Accuracy:0.9518, ROC:0.9312, F1:0.9642 Combination by w_vote| Accuracy:0.9649, ROC:0.9644, F1:0.9728 Combination by median| Accuracy:0.9693, ROC:0.9677, F1:0.9763
聚类组合示例
“examples/cluster_comb_example.py” 演示了组合多个基本聚类估计器的基本 API。“examples/cluster_eac_example.py” 演示了使用证据积累 (EAC) 组合多个聚类的基本 API。
将一组聚类方法初始化为基本估计器
# Initialize a set of estimators estimators = [KMeans(n_clusters=n_clusters), MiniBatchKMeans(n_clusters=n_clusters), AgglomerativeClustering(n_clusters=n_clusters)]初始化一个 Clusterer Ensemble 类并拟合模型
from combo.models.cluster_comb import ClustererEnsemble # combine by Clusterer Ensemble clf = ClustererEnsemble(estimators, n_clusters=n_clusters) clf.fit(X)得到对齐的结果
# generate the labels on X aligned_labels = clf.aligned_labels_ predicted_labels = clf.labels_
异常值检测器组合示例
“examples/detector_comb_example.py” 演示了组合多个基本异常检测器的基本 API。
将一组异常检测方法初始化为基本估计器
# Initialize a set of estimators detectors = [KNN(), LOF(), OCSVM()]初始化一个简单的平均聚合器,拟合模型并进行预测。
from combo.models.detector combination import SimpleDetectorAggregator clf = SimpleDetectorAggregator(base_estimators=detectors) clf_name = 'Aggregation by Averaging' clf.fit(X_train) y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores # get the prediction on the test data y_test_pred = clf.predict(X_test) # outlier labels (0 or 1) y_test_scores = clf.decision_function(X_test) # outlier scores使用 ROC 和 Precision @ Rank n 评估预测。
# evaluate and print the results print("\nOn Training Data:") evaluate_print(clf_name, y_train, y_train_scores) print("\nOn Test Data:") evaluate_print(clf_name, y_test, y_test_scores)查看训练和测试数据的样本输出。
On Training Data: Aggregation by Averaging ROC:0.9994, precision @ rank n:0.95 On Test Data: Aggregation by Averaging ROC:1.0, precision @ rank n:1.0
发展状况
截至 2020 年 2 月,组合目前正在开发中。已经制定了具体计划,并将在未来几个月内实施。
与我们构建的其他库类似,例如 Python Outlier Detection Toolbox ( pyod ), combo也有针对性地发表在Journal of Machine Learning Research (JMLR)开源 软件轨道上。已在 AAAI 2020中提交了一份演示论文以进行进度更新。
观看并加注星标以获取最新更新!也请随时给我发送电子邮件 ( zhaoy@cmu.edu )以获取建议和想法。
纳入标准
与 scikit-learn 类似,我们主要考虑完善的包含算法。经验法则是自出版以来至少两年,被引用超过 50 次,并且有用。
但是,我们鼓励新提议模型的作者分享您的实现并将您的实现添加到组合中,以提高 ML 可访问性和可重复性。仅当您可以承诺将模型维护至少两年时,此例外情况才适用。


